Friday, July 31st, 2026 at 3:33 PM
Software physics
I like Andy Matuschak's use of the word "physics" to describe a set of rules in software tn his talk on the possibilities LLMs open up for programming. Two examples:
CodeMirror defines a rough physics of the medium: basic models for text, state, and selection, with transactional updates.
So, by way of generalizing from CodeMirror: could we define a physics of reading environments—one which could simultaneously support all these disparate augmented reading ideas, plus untold more yet to be invented?
Wednesday, July 29th, 2026 at 10:20 AM
Art as compression
David Hockney talking about the difference between photography and painting:
...the reason you can’t look at a photograph for a long time is because there’s virtually no time in it - the imbalance between the two experiences, the first and second lookings, is too extreme.
I think you could poke holes in this, but I like the model:
Monday, July 27th, 2026 at 10:53 AM
Document editor
Trying out canvas-based paragraph reordering pared with a live document preview.
Wednesday, July 22nd, 2026 at 10:41 AM
Digital table fidget
Wednesday, July 22nd, 2026 at 10:41 AM
Digital table fidget
Tuesday, July 21st, 2026 at 3:24 PM
New physical computing setup
Thursday, July 16th, 2026 at 2:14 PM
Branch
New on Constraint Systems:
Branch - a collaborative collage of tree and branch photos. Take a photo and trace the flow to add to a branch.
Sunday, July 12th, 2026 at 9:08 AM
The Stone Sky
 by N.K. Jemisin
by N.K. Jemisin
I moved a little slower through this one, mostly because I found a lot of the Nassun chapters tough (not in a bad way, just in an "I'm nervous for her" way).
There was a lot of lore to get through and resolve since it's the conclusion. Sometimes it felt like it was speeding through things, but by the end I was really happy with the full picture. Most of my questions were answered. it's still very small slices/vignettes from a much larger history. There's a world where I would have been interested to read more chapters from more perspectives, including more slice-of-life stuff, but that's also a different book.
Thursday, July 9th, 2026 at 12:45 PM
Blog rework and composition
Today I started in on blog revamp. Partly because I wanted to experiment with Matt Pocock's LLM skill workflow in a relatively conventional app (not a weird Constraint Systems experiment). Also because I've been feeling the edges of my current setup. Overall I'm thinking about how I want my software and computer to work in a world where LLMs make adding features/cheap.
Surface area
In the wave of LLM-assisted demos I think a lot about surface area. Adding features adds surface area. Particularly when the features are just kind of additional nice-to-haves. It can feel different if the features grow out of the center of the idea. That's like a tree growing out of a core. A bunch of ad-hoc features is a loosely connected collection of graphs, floating and tangling up into eachother.
Wednesday, July 1st, 2026 at 4:38 PM
Constraint Browsers
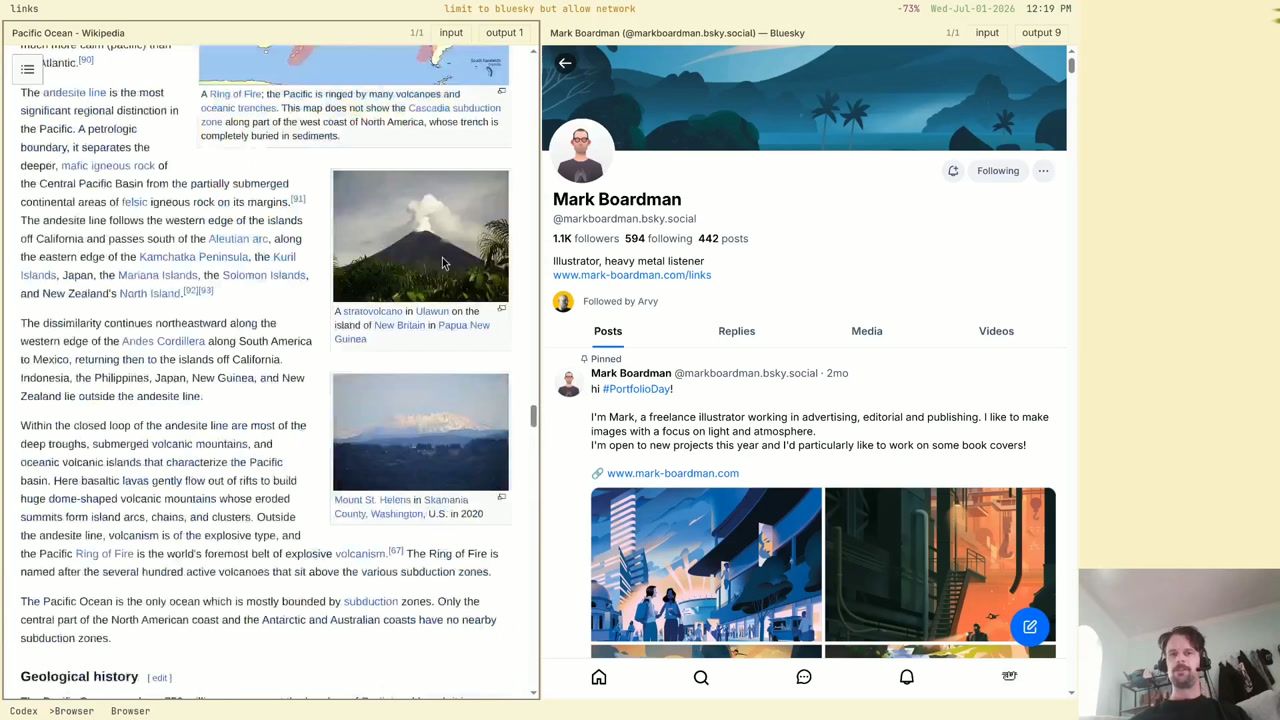
Experimenting with mini-browsers limited to specific urls or domains. Clicking on external links saves them to a list (that possibly you then feed into a different mini browser?). Recorded some thoughts on youtube.
Thinking about making a browser feel more like a place (thinking of Interface Studies' video). Also thinking of the satisfaction and clarity of plugging a cartridge/disk into a system.
Monday, June 29th, 2026 at 3:12 PM
Writerdeck prototype
Put together a prototype writerdeck with the modos dev kit. Direct sunlight does work. It's a bit bulky and I should probably use one of my minimal low-profile keyboards, but I do love typing on the kinesis the most. In some other world I'd cut up and mod the kinesis body directly.
 The currrent prototype.
The currrent prototype.
 The pieces laid out.
The pieces laid out.
Saturday, June 27th, 2026 at 4:27 PM
Cosine grid
Experimenting with putting the embedded texts from Cosine into UMAP and then fitting to a grid. Not as glanceable as images would be but I think there's probably some interesting moves to make here.
Thursday, June 25th, 2026 at 9:46 AM
Topic continents
Wikimedia concepts embedded and then mapped to a sphere with UMAP. Trying out topic clusters as continents. Not sure where it's all going.
Wednesday, June 24th, 2026 at 11:59 AM
Tile distortion debug
 More sphere work
More sphere work
Wednesday, June 24th, 2026 at 10:44 AM
The Obelisk Gate
 by N.K. Jemisin
by N.K. Jemisin
I'm trying to spread out the series I read so it is a testament to how good The Fifth Season is that I jumped into this immediately.
The dedication is "For those who have no choice but to prepare their children for the battlefield" and you feel that all the way through the book. The relationship between Essun and Nassun is so well developed on both sides. Clear-eyed in the pain caused eac hother but also the reasons for it. It always feels like it is reporting, rather than pleading any one character's case.
Tuesday, June 23rd, 2026 at 11:16 AM
Reader
Putting together a personal RSS reader that shows the original articles. With vim-style navigation.
Wednesday, June 17th, 2026 at 5:55 PM
clinamen v.11 by Céleste Boursier-Mougenot
I saw the bowls (clinamen v.11 by Céleste Boursier-Mougenot). A perfect generative piece because you can immediately understand how it operates but the results are no less magical. It feels very like something from nature in that way.
It was nice to be around a bunch of other people who decided it was something worth making the effort to see.

Tuesday, June 16th, 2026 at 11:51 AM
The Fifth Season
 by N.K. Jemisin
by N.K. Jemisin
The first time I read this I hadn't read much fantasy. Having read and enjoyed a bunch now this still stands out. I also hadn't read The Ones Who Walk Away from Omelas. Having that context - that the conversation about "who are you willing to sacrifice" has this history of being explored through sci-fi - added another layer.
The standout things for me are the world-building and the main character.
Monday, June 15th, 2026 at 3:09 PM
Sphere tiling
Experimenting more with tiling at different levels-of-detail on a sphere. Trying to make a little world.

